
 Erik Mitisek
Erik Mitisek
4 Ways Brokers Can Use Data To Grow Revenue
Insurance runs on data. Accurate data is essential to understanding risk, accurately pricing policies, and providing services to complement...

If you’re like many commercial insurance leaders, you may have a long list of innovation projects or insurtech solutions that haven’t delivered as promised. Relying on inefficient manual methods and disconnected systems is frustrating, especially when you don’t know what can make everything work better.
Whether you’re launching your first innovation project or renewing an existing effort, upgrading your data quality is a great place to start and a critical step for any innovation journey.
Being in the business of predicting risk, bad data equates to bad predictions. For that reason, no digital transformation can succeed without data you can easily trust, access, and share; especially in insurance.
The various insurance broker software systems that house data store it in different formats; most of which are proprietary. This leads to similar data being stored in multiple formats across disconnected systems. Disconnected systems and unformatted data can lead to unreliable data, and even the best innovation programs will fail if they are built off of faulty data. Insight programs will fail because faulty data will taint the decision making process with inaccurate and erroneous information. Connectivity programs will fail because unstructured, non-standardized, and incomplete data cannot be easily shared between systems.
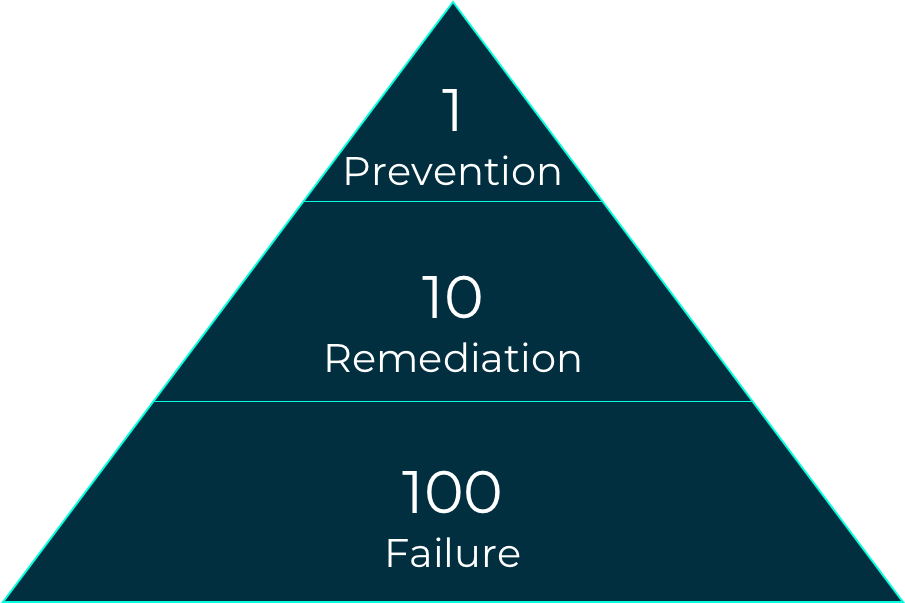
The 1-10-100 rule is a quality management framework illustrating the approximate costs of quality related failures
Obviously, data can’t be trusted and useful unless it’s accurate, up-to-date, and complete. Without trustworthy data, users must constantly verify and correct it -- adding time, cost, and frustration for both brokers and their clients. In short, Insights generated from bad data can’t effectively guide sound business decisions.
Bad data costs time and money. Some experts estimate that it costs 10 times as much to fix defective data as it does to stop it from entering your systems in the first place. IBM estimates that bad data costs US companies a total of $3.1 trillion annually.

Efficient insurance workflows depend on data being shared across interconnected systems. Each system needs to speak a common language so data can be understood by and flow seamlessly between them. Data standardization and normalization is needed to transform all data into a common format both systems can handle.
When data is standardized, normalized, and accurate, you gain a common language so your systems can work together. You also gain a single source of truth, connected and scalable workflows, and the ability to use data to generate valuable insights.
High-quality data is:
|
Correct |
Is it accurate and free of errors? |
|
Current |
Is it up to date? |
|
Complete |
Are you collecting the right data (fields)? Are those fields complete across your entire data set? |
|
Consistent |
Is the data expressed in a consistent syntax and standard form that can be commonly understood and shared across systems? |
To understand your brokerage’s data quality, you’ll want to extract a sample and assess it using a structured approach. It’s best to focus on a single workflow at a time.

Start by determining what data and data sources you need to power your workflow. For example, let’s take the policy renewal process.
Compare what fields of data you have to what the carrier requires for a complete renewal application. Often, carriers require more fields of data than brokers routinely collect. For instance, a carrier may require 63 fields as part of their renewal process but a broker may only collect 23 fields of data, and some of those fields may be blank or out of date.
What data sources do you currently use to populate those 63 fields? Typically, for renewals you might pull the 23 fields from your internal systems, and then collect the rest from your insureds and third party sources. Identify all sources used and how that data is collected.

Next, evaluate your data’s quality. The goal is to identify:
Evaluating your own insurance data quality is a fairly tedious exercise that requires more time than expertise. Data expert Thomas Redman recommends making this easier by committing to two-hour weekly data quality reviews. Over time, you’ll fix any data problems, particularly if you also take steps to prevent any new bad data from entering your systems.
If you’re too busy to run your own data quality assessment, let us help. Highwing provides complementary data quality assessments for qualified insurance brokers. We’ll diagnose your current data state by mapping your data fields to our proprietary data model to produce a comprehensive, personalized data quality report. We’ll help you understand your data’s overall completeness and conformance scoring along with additional detail spanning your client, policy, and agency fields.
Once you’ve got an accurate read on your data quality, you can then make a plan for improving it. We’ll cover this process in our next post - stay tuned!
To request Highwing’s complementary data assessment, get in touch.

Insurance runs on data. Accurate data is essential to understanding risk, accurately pricing policies, and providing services to complement...

“The best way to predict the future is to create it.” – Peter Drucker

In the heart of Atlanta, a prominent insurance broker found themselves slipping among their competition. The company had grown into a formidable...